Implementing KNN from Scratch
K Nearest Neighbors in Python and NumPy


Last update: 26.03.2023. All opinions are my own.
1. Overview
This blog post provides a tutorial on implementing the K Nearest Neighbors algorithm using Python and NumPy. We will set up a simple class object, implement relevant methods to perform the prediction, and illustrate how it works on a toy dataset.
Why are we implementing KNN from scratch if the algorithm is already available in scikit-learn? First, coding something from scratch is the best way to understand it. You may know many ML algorithms, but being able to write it down indicates that you have really mastered it. Second, implementing algorithms from scratch is a common task in ML interviews in tech companies, which makes it a useful skill that a job candidate should practice. Last but not least, it's a fun exercise, right? :)
This post is part of "ML from Scratch" series, where we implement established ML algorithms in Python. Check out other posts to see further implementations.
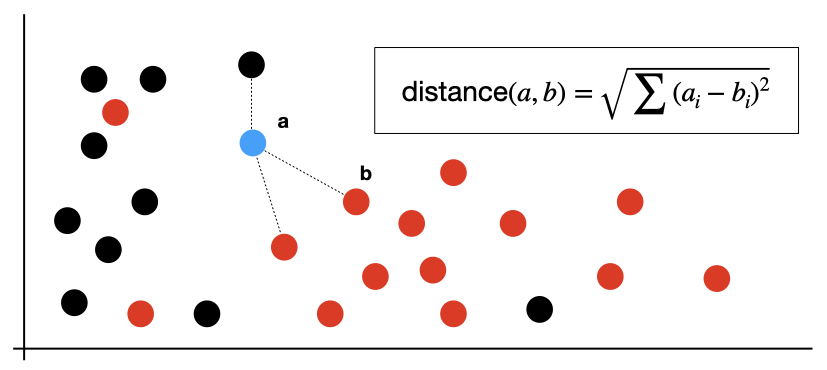
2. How KNN works
Before we jump to the implementation, let's quickly refresh our minds. How does KNN work?
KNN is one of the so-called lazy algorithms, which means that there is no actual training step. Instead, KNN memorizes the training data by storing the feature values of training examples. Given a new example to be predicted, KNN calculates distances between the new example and each of the examples in the training set. The prediction returned by the KNN algorithm is simply the average value of the target variable across the K nearest neighbors of the new example.
P.S. If you need a more detailed summary of how KNN works, check out this Wiki page.
for size in layer_sizes:
x = tf.keras.layers.Dense(
size,
kernel_initializer="he_uniform",
activation=activation_fn,
)(x)
if size < layer_sizes - 1:
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Dropout(dropout_rate)(x)
x = tf.keras.layers.Dense(
n_outputs, kernel_initializer="he_uniform", activation="sigmoid", name="events_predictions"
)(x)
import numpy as np
In line with object-oriented programming practices, we will implement KNN as a class with a set of methods. We will need the following five:
-
__init__(): initialize the class object. -
fit(): memorize the training data and store it as a class variable. -
predict(): predict label for a new example. -
get_distance(): helper function to calculate distance between two examples. -
get_neighbors(): helper function to find and rank neighbors by distance.
The last two functions are optional: we can implement the logic inside the predict() method, but it will be easier to split the steps.
Let's sketch a class object template. Since we implement functions as class methods, we include self argument for each method:
class KNN:
def __init__(self):
pass
def fit(self):
"""
Memorize training data
"""
pass
def predict(self):
"""
Predict labels
"""
pass
def get_distance(self):
"""
Calculate distance between two examples
"""
pass
def get_neighbors(self):
"""
Find nearest neighbors
"""
pass
Now let's go through each method one by one.
The __init__() method is run once when the initialize the KNN class object. The only thing we need to do on the initialization step is to store meta-parameters of our algorithm. For KNN, there is only one key meta-parameter we specify: the number of neighbors. We will save it as self.num_neighbors:
def __init__(self, num_neighbors: int = 5):
self.num_neighbors = num_neighbors
Next, let's implement the fit() method. As we mentioned above, on the training stage, KNN needs to memorize the training data. To simplify further calculations, we will provide the input data as two numpy arrays: features saved as self.X and labels saved as self.y:
def fit(self, X: np.array, y: np.array):
"""
Memorize training data
"""
self.X = X
self.y = y
Now, let's write down a helper function to calculate distance between two examples, which are two numpy arrays with feature values. For simplicity, we will assume that all features are numeric. One of the most commonly used distance metrics is the Euclidean distance, which is calculated as a root of the sum of the squared differences between feature values. If the last sentence sounds complicated, here is how simple it looks in Python:
def get_distance(self, a: np.array, b: np.array):
"""
Calculate Euclidean distance between two examples
"""
return np.sum((a - b) ** 2) ** 0.5
Now we are getting to the most difficult part of the KNN implementation! Below, we will write a helper function that finds nearest neighbors for a given example. For that, we will do several steps:
- Calculate distance between the provided example and each example in the memorized dataset
self.X. - Sort examples in
self.Xby their distances to the provided example. - Return indices of the nearest neighbors based on the
self.num_neighborsmeta-parameter.
For step 1, we will leverage the get_distance() function defined above. The trick to implement step 2 is two save a tuple (example ID, distance) when going through the training data. This will allow to sort the examples by distance and return the relevant IDs at the same time:
def get_neighbors(self, example: np.array):
"""
Find and rank nearest neighbors of example
"""
# placeholder
distances = []
# calculate distances as tuples (id, distance)
for i in range(len(self.X)):
distances.append((i, self.get_distance(self.X[i], example)))
# sort by distance
distances.sort(key = lambda x: x[1])
# return IDs and distances top neighbors
return distances[:self.num_neighbors]
The final step is to do the prediction! For this purpose, we implement the predict() method that expects a new dataset as a numpy array and provides an array with predictions. For each example in the new dataset, the method will go through its nearest neighbors identified using the get_neighbors() helper, and average labels across the neighbors. That's it!
def predict(self, X: np.array):
"""
Predict labels
"""
# placeholder
predictions = []
# go through examples
for idx in range(len(X)):
example = X[idx]
k_neighbors = self.get_neighbors(example)
k_y_values = [self.y[item[0]] for item in k_neighbors]
prediction = sum(k_y_values) / self.num_neighbors
predictions.append(prediction)
# return predictions
return np.array(predictions)
Putting everything together, this is how our implementation looks like:
### END-TO-END KNN CLASS
class KNN:
def __init__(self, num_neighbors: int = 5):
self.num_neighbors = num_neighbors
def fit(self, X: np.array, y: np.array):
"""
Memorize training data
"""
self.X = X
self.y = y
def get_distance(self, a: np.array, b: np.array):
"""
Calculate Euclidean distance between two examples
"""
return np.sum((a - b) ** 2) ** 0.5
def get_neighbors(self, example: np.array):
"""
Find and rank nearest neighbors of example
"""
# placeholder
distances = []
# calculate distances as tuples (id, distance)
for i in range(len(self.X)):
distances.append((i, self.get_distance(self.X[i], example)))
# sort by distance
distances.sort(key = lambda x: x[1])
# return IDs and distances top neighbors
return distances[:self.num_neighbors]
def predict(self, X: np.array):
"""
Predict labels
"""
# placeholder
predictions = []
# go through examples
for idx in range(len(X)):
example = X[idx]
k_neighbors = self.get_neighbors(example)
k_y_values = [self.y[item[0]] for item in k_neighbors]
prediction = sum(k_y_values) / self.num_neighbors
predictions.append(prediction)
# return predictions
return np.array(predictions)
### HELPER FUNCTION
def gen_data(
mu: float = 0,
sigma: float = 1,
y: int = 0,
size: tuple = (1000, 10),
):
"""
Generate random data
"""
X = np.random.normal(loc = mu, scale = sigma, size = size)
y = np.repeat(y, repeats = size[0])
return X, y
To simulate a simple ML problem, we will generate a dataset consisting of two samples:
- 30 examples with mean features value of 1 and a label of 0.
- 20 examples with mean features value of 5 and a label of 1.
### TOY DATA GENERATION
X0, y0 = gen_data(mu = 1, sigma = 3, y = 0, size = (30, 10))
X1, y1 = gen_data(mu = 5, sigma = 3, y = 1, size = (20, 10))
X = np.concatenate((X0, X1), axis = 0)
y = np.concatenate((y0, y1), axis = 0)
Now, let's instantiate our KNN class, fit it on the training data and provide predictions for some new examples!
To see if the algorithm works properly, we will generate four new examples as X_new, gradually increasing the feature values from 1 to 5. We expect the label predicted by KNN to increase from 0 to 1, since we are getting closer to examples in X1. Let's check!
### PREDICTION
# fit KNN
clf = KNN(num_neighbors = 5)
clf.fit(X, y)
# generate new examples
X_new = np.stack((
np.repeat(1, 10),
np.repeat(2, 10),
np.repeat(4, 10),
np.repeat(5, 10),
))
# predict new examples
clf.predict(X_new)
Yay! Everything works as expected. Our KNN algorithm provides four predictions for the new examples, and the prediction goes up with the increase in feature values. Our job is done!
5. Closing words
This is it! I hope this tutorial helps you to refresh your memory on how KNN works and gives you a good idea on how to implement it yourself. You are now well-equipped to do this exercise on your own!
If you liked this tutorial, feel free to share it on social media and buy me a coffee :) Don't forget to check out other posts in the "ML from Scratch" series. Happy learning!
Liked the post? Share it on social media!
You can also buy me a cup of coffee to support my work. Thanks!
