

Portfolio
My public ML portfolio includes projects on different topics, including generative AI, NLP, computer vision, and tabular data. To see more of my work, visit my GitHub page, download my CV or check out the about page.
My public ML portfolio includes projects on different topics, including generative AI, NLP, computer vision, and tabular data. To see more of my work, visit my GitHub page, download my CV or check out the about page.
My portfolio features the following projects:
- 📖 Text reading complexity prediction with transformers
- 🧬 Image-to-text translation of chemical structures with deep learning
- 📈 Fair machine learning in credit scoring applications
Scroll down to see more generative AI and ML projects grouped by application domains. Click "read more" to see project summaries, and follow GitHub links for code and documentation.
Text Readability Prediction with Transformers

Highlights
- developed a comprehensive PyTorch / HuggingFace text classification pipeline
- build multiple transformers including BERT and RoBERTa with custom pooling layers
- implemented an interactive web app for custom text reading complexity estimation
Tags: natural language processing, deep learning, web app
Summary
Estimating text reading complexity is a crucial task for school teachers. Offering students text passages at the right level of challenge is important for facilitating a fast development of reading skills. The existing tools to estimate text complexity rely on weak proxies and heuristics, which results in a suboptimal accuracy. In this project, I use deep learning to predict the readability scores of text passages.
My solution implements eight transformer models, including BERT, RoBERTa and others in PyTorch. The models feature a custom regression head that uses a concatenated output of multiple hidden layers. The modeling pipeline includes text augmentations such as sentence order shuffle, backtranslation and injecting target noise. The solution places in the top-9% of the Kaggle competition leaderboard.
The project also includes an interactive web app built in Python. The app allows to estimate reading complexity of a custom text using two of the trained transformer models. The code and documentation are available on GitHub.
Image-to-Text Translation of Molecules with Deep Learning

Highlights
- built a CNN-LSTM encoder-decoder architecture to translate images into chemical formulas
- developed a comprehensive PyTorch GPU/TPU image captioning pipeline
- finished in the top-5% of the Kaggle competition leaderboard with a silver medal
Tags: computer vision, natural language processing, deep learning
Summary
Organic chemists frequently draw molecular work using structural graph notations. As a result, decades of scanned publications and medical documents contain drawings not annotated with chemical formulas. Time-consuming manual work of experts is required to reliably convert such images into machine-readable formulas. Automated recognition of optical chemical structures could speed up research and development in the field.
The goal of this project is to develop a deep learning based algorithm for chemical image captioning. In other words, the project aims at translating unlabeled chemical images into the text formula strings. To do that, I work with a large dataset of more than 4 million chemical images provided by Bristol-Myers Squibb.
My solution is an ensemble of CNN-LSTM Encoder-Decoder models implemented in PyTorch.The solution reaches the test score of 1.31 Levenstein Distance and places in the top-5% of the competition leaderboard. The code is documented and published on GitHub.
Fair Machine Learning in Credit Scoring
Highlights
- benchmarked eight fair ML algorithms on seven credit scoring data sets
- investigated profit-fairness trade-off to quantify the cost of fairness
- published a paper with the results at the European Journal of Operational Research
Tags: tabular data, fairness, profit maximization
Summary
The rise of algorithmic decision-making has spawned much research on fair ML. In this project, I focus on fairness of credit scoring decisions and make three contributions:
- revisiting statistical fairness criteria and examining their adequacy for credit scoring
- cataloging algorithmic options for incorporating fairness goals in the ML model development pipeline
- empirically comparing different fairness algorithms in a profit-oriented credit scoring context using real-world data
The code and documentation are available on GitHub. A detailed walkthrough and key results are published in this paper.
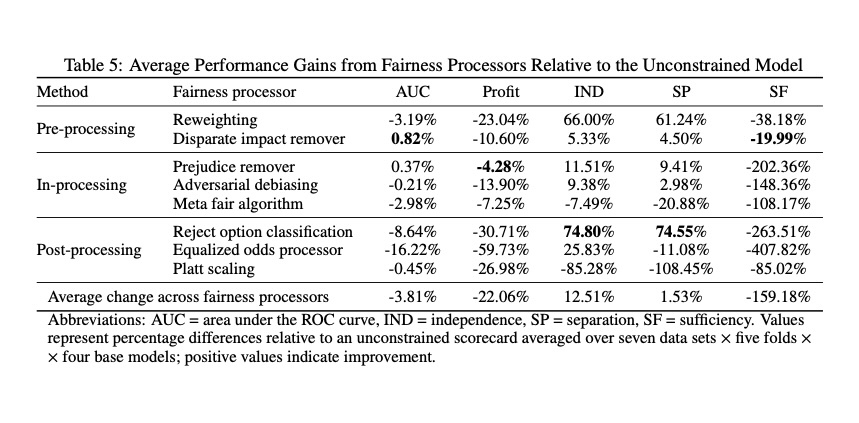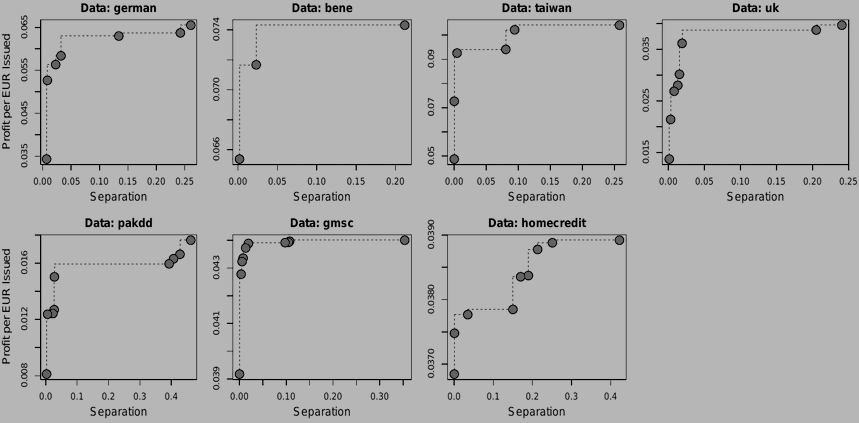
The study reveals that multiple fairness criteria can be approximately satisfied at once and recommends separation as a proper criterion for measuring scorecard fairness. It also finds fair in-processors to deliver a good profit-fairness balance and shows that algorithmic discrimination can be reduced to a reasonable level at a relatively low cost.
Further projects
Want to see more? Check out my further ML projects grouped by application areas below. You can also visit my GitHub page, check my recent blog posts, watch public tech talks and read academic publications.
Medical Content Generation with LLMs
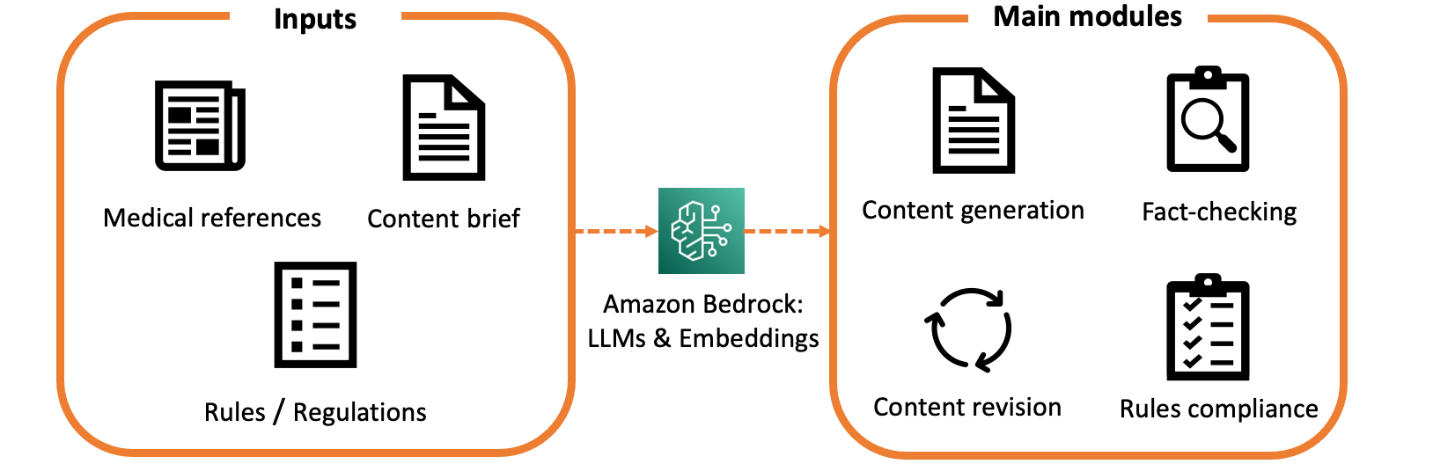
- developed LLM-powered end-to-end content generation solution on AWS
- the system provides generation, revision, and fact-checking capabilities
- implemented an interactive web app and backend as infrastructure-as-code
Improving RAG with User Interaction Tool
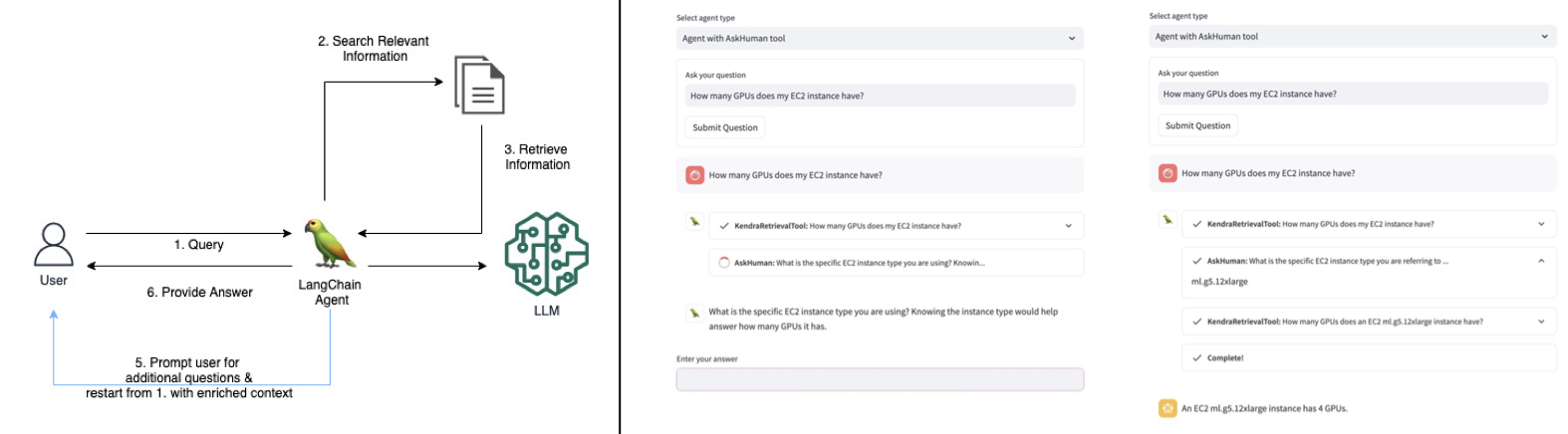
- integrated a human feedback tool into a RAG agent
- published a blog post and the code of the solution
Pet Popularity Prediction

- built a PyTorch pipeline for predicting pet cuteness from image and tabular data
- reached top-4% in the Kaggle competition using Transformers and CNNs
- implemented an interactive web app for estimating cuteness of custom pet photos
Cassava Leaf Disease Classification

- built CNNs and Vision Transformers in PyTorch to classify plant diseases
- constructed a stacking ensemble with multiple computer vision models
- finished in the top-1% of the Kaggle competition with a gold medal
Catheter and Tube Position Detection on Chest X-Rays

- built deep learning models to detect catheter and tube position on X-ray images
- developed a comprehensive PyTorch GPU/TPU computer vision pipeline
- finished in the top-5% of the Kaggle competition leaderboard with silver medal
Detecting Blindness on Retina Photos

- developed CNN models to identify disease types from retina photos
- written a detailed report covering problem statement, EDA and modeling
- submitted as a capstone project within the Udacity ML Engineer program
Probabilistic Demand Forecasting with Graph Neural Networks
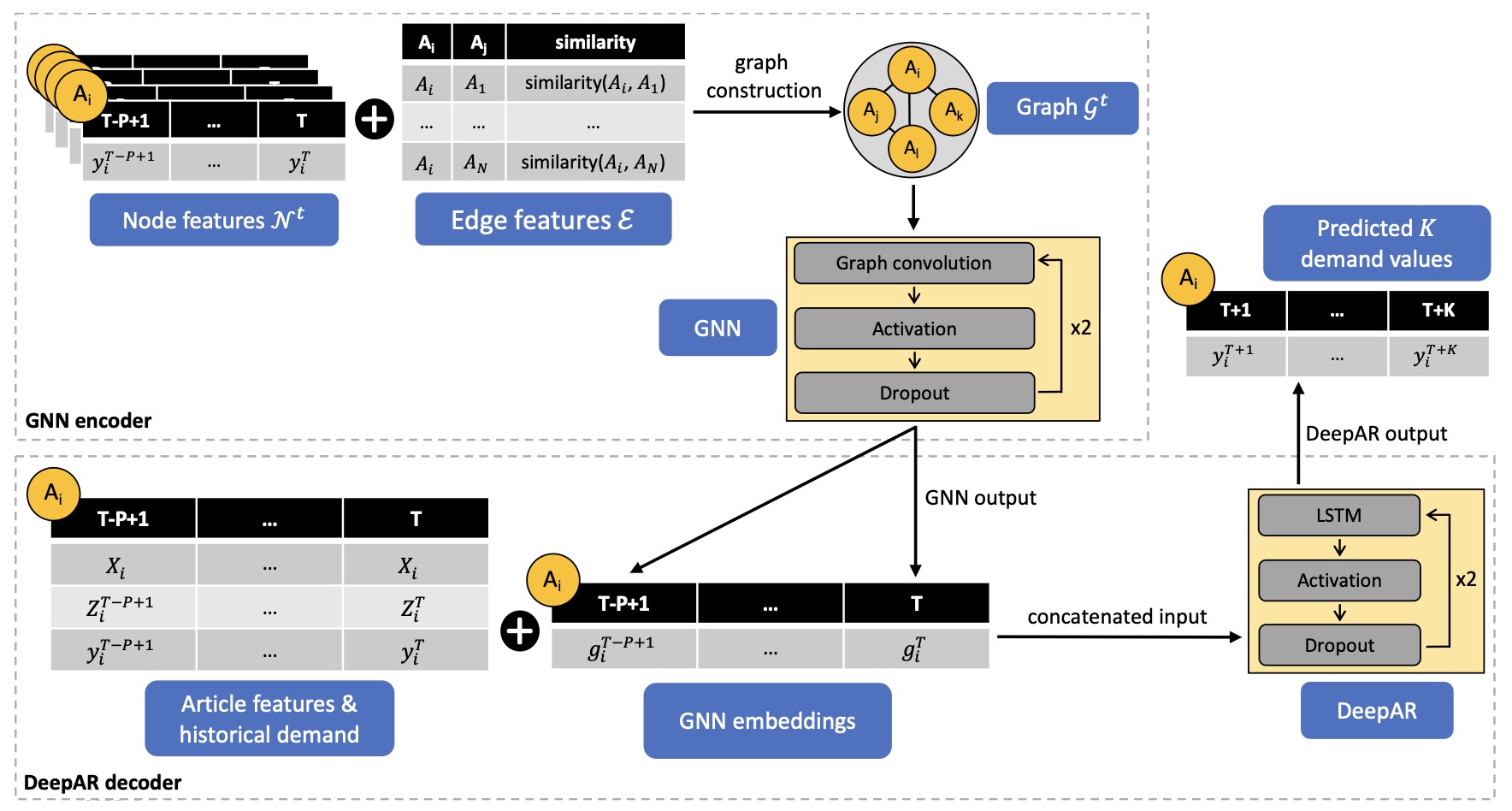
- developed a novel probabilistic demand forecasting architecture combining GNNs and DeepAR
- proposed article similarity based data-driven similarity matrix construction
- published a paper demonstrating monetary and accuracy gains from the proposed model
Profit-Driven Demand Forecasting with Gradient Boosting
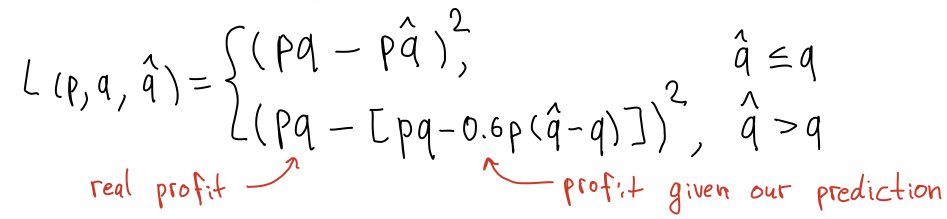
- developed a two-stage demand forecasting pipeline with LightGBM models
- performed a thorough cleaning, aggregation and feature engineering on transactional data
- implemented custom loss functions aimed at maximizing the retailer's profit
Google Analytics Customer Revenue Prediction
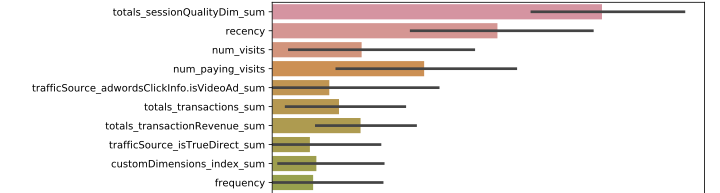
- worked with two-year transactional data from a Google merchandise store
- developed LightGBM models to predict future revenues generated by customers
- finished in the top-2% of the Kaggle competition leaderboard with silver medal
fairness: Package for Computing Fair ML Metrics
- developing and actively maintaining an R package for fair machine learning
- the package offers calculation, visualization and comparison of algorithmic fairness metrics
- the package is published on CRAN and has more than 16k total downloads
